Как работают RAG и методы построения RAG систем
Что Вы узнаете:
- Что такое RAG (Retrieval-Augmented Generation) и как оно работает
- Какие методы используются для построения RAG-систем
- Какие преимущества дает RAG перед стандартными языковыми моделями
- Какие инструменты и библиотеки помогают реализовать RAG
- Как обучить и настроить RAG-систему для своих задач
RAG (Retrieval-Augmented Generation) — это мощный метод, который совмещает генеративные языковые модели с механизмами поиска информации. Это позволяет улучшить качество ответов, делать их более актуальными и подкреплять фактическими данными. Если вы хотите разобраться в принципах работы RAG, понять, какие алгоритмы и библиотеки используются для его реализации, а также узнать, как адаптировать его под свои задачи, эта статья вам поможет.
Процесс Retrieval-Augmented Generation (RAG) представляет собой довольно сложную систему, состоящую из множества компонентов. Вопрос о том, как определить существующие методы RAG и их оптимальные комбинации для выявления лучших практик, в настоящий момент остается наиболее актуальным. В этой статье я хочу поделиться своим опытом относительно реализации подходов и практик в области RAG систем, который реализует систематический подход к решению этой проблемы.
Типовые задачи процессов RAG систем
- Классификация запросов,
- Деление на фрагменты
- Векторизация данных
- Поиск,
- Переранжирование,
- Обобщение данных .
- Генерация ответа
Каждый из этих этапов играет важную роль в обеспечении точности и эффективности системы. Например, классификация запросов помогает определить, нужно ли вообще выполнять поиск, что может значительно сократить время обработки. Переранжирование и переупаковка документов улучшают релевантность результатов, а обобщение помогает устранить избыточность и улучшить качество ответов.
На мой взгляд, ключевая сложность RAG заключается в том, что каждый этап требует тщательной настройки и выбора оптимальных методов. Например, как выбрать размер фрагментов для поиска? Какую эмбеддинг модель использовать? Эти вопросы требуют не только теоретического анализа, но и практических экспериментов.
Попробуем рассмотреть все этапы разработки участвующие в структуре обработке данных RAG систем

Как видно из визуализации необходимых шагов разработки, задачи делятся на три уровня уровень подготовки, обработки и классификации запроса, уровень подготовки, разделения, векторизации и хранения документов и уровень переранжирования, генерации и обобщения ответа. Схематично все этапы можно представить в виде схемы:
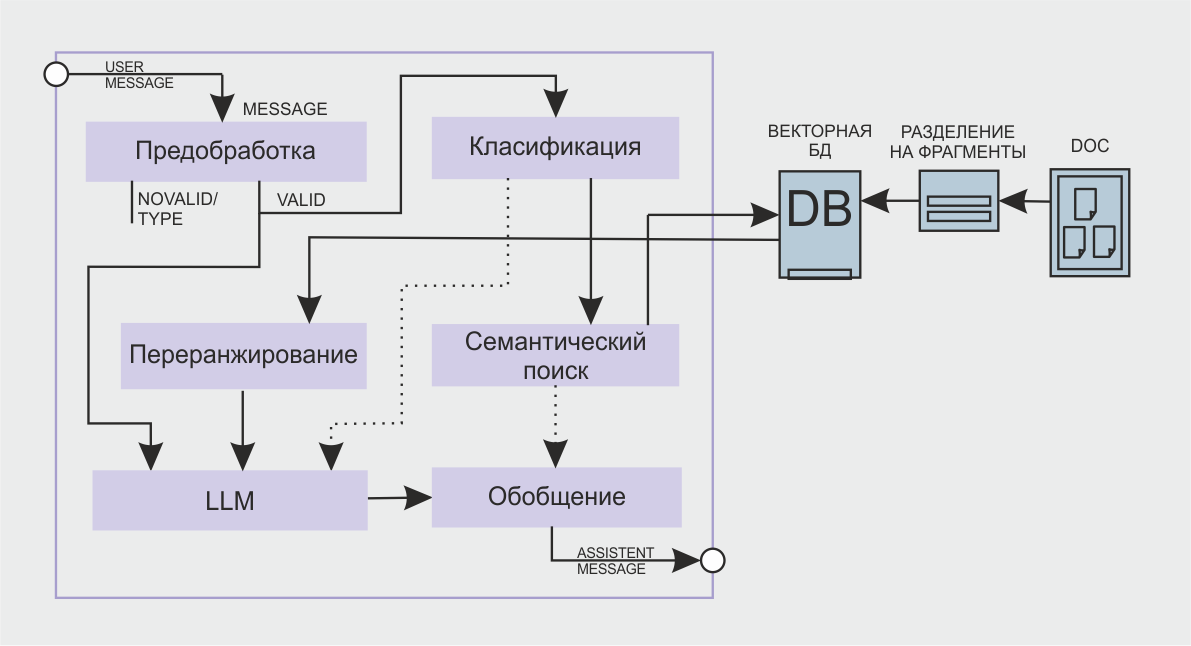
Рассмотрим все этапы поочередно.
Вот профессиональный рерайт вашего текста с добавленными заголовками и улучшением структуры:
Классификация запросов: ключевой этап для успешного поиска информации
Классификация запросов — это важный шаг в процессе обработки информации, который позволяет точно определить, требует ли запрос дальнейшего поиска или достаточно имеющихся знаний в системе. Не всегда запросы требуют дополнительного поиска, и это особенно актуально в контексте использования больших языковых моделей (LLM, Large Language Models), которые уже могут хранить значительный объём информации.
Как классифицировать запросы?
Определение типа запроса играет решающую роль в процессе принятия решения о необходимости поиска. Рассмотрим основные категории запросов:
- Фактический запрос
Пример: «Сколько стоит построить дом?»
Этот запрос требует точной информации, которую можно найти в базе данных или на веб-ресурсах. - Мнение или оценка
Пример: «Что лучше: кирпичный или каркасный дом?»
Здесь нет единственно правильного ответа, и необходимы суждения или мнения, основанные на опыте. - Рассуждения или синтез информации
Пример: «Где лучше выбрать землю для строительства?»
Этот запрос требует анализа множества факторов и оценки данных из разных источников. - Личный или неформальный запрос
Пример: «Как ты думаешь, лучше построить дом или жить в квартире?»
Ответ на такой запрос часто носит субъективный характер, основанный на личных предпочтениях или опыте.
Стратегии поиска для разных типов запросов
После того как запрос классифицирован, необходимо выбрать стратегию поиска, которая будет наиболее эффективной для получения ответа:
- Для фактической информации
Если запрос касается конкретных фактов, используется поиск в базе данных или векторный поиск, который помогает быстро найти нужные данные. - Для сложных запросов
Когда запрос включает несколько аспектов, комбинируются несколько источников информации для создания более полных и точных ответов. - Для простых запросов
В случае запросов, ответы на которые уже известны или могут быть легко предоставлены, LLM модель может дать ответ напрямую, без необходимости дополнительного поиска.
Как фильтровать и модерировать запросы?
Важно обеспечить качественную фильтрацию и модерацию запросов, чтобы избежать неуместной или потенциально вредоносной информации. Это включает несколько ключевых аспектов:
- Проверка на наличие запрещённого контента.
- Обнаружение токсичных выражений и неприемлемых тем.
- Защита конфиденциальности данных пользователя.
- Выявление нерелевантных или потенциально вредных запросов.
Методы классификации запросов
Для эффективной классификации запросов используется несколько подходов, среди которых выделяются:
- Лингвистический анализ
Это метод, при котором анализируется структура предложения, а также ключевые слова, что позволяет понять, о каком типе запроса идет речь. - Модели машинного обучения (ML)
Применение обученных моделей, таких как BERT или GPT, позволяет классифицировать запросы, основываясь на размеченных данных. Эти модели могут эффективно различать типы запросов и выбирать соответствующую стратегию обработки. - Правила и эвристики
В некоторых случаях используются простые правила и эвристические методы, такие как поиск вопросительных слов или фраз, характерных для запросов определённого типа.
Пример классификации с использованием BERT
Пример классификации запросов можно реализовать с помощью библиотеки transformers и модели BERT. Эта модель позволяет точно классифицировать запросы по типам, что делает процесс обработки данных более быстрым и точным.
В результате, правильно выполненная классификация запросов помогает значительно улучшить качество поиска и взаимодействие с пользователем, делая систему более эффективной и гибкой.
Пример классификации запросов с использованием библиотеки transformers и модели BERT
import torch
from transformers import pipeline
# Загружаем предобученную модель для классификации
classifier = pipeline("zero-shot-classification", model="facebook/bart-large-mnli")
# Возможные классы запросов
labels = ["фактический поиск", "мнение", "рассуждение", "личный вопрос", "неопределённый"]
# Функция классификации запроса
def classify_query(query):
result = classifier(query, candidate_labels=labels)
return result["labels"][0], result["scores"][0]
# Примеры запросов
queries = [
"Сколько стоит построить дом?",
"Как ты думаешь, погрузчик лучше, чем экскаватор?",
"Объясни принципы работы ДВС.",
"Стоит ли мне переехать в другой город?",
"Просто хочу поговорить."
]
# Классифицируем запросы
for query in queries:
label, score = classify_query(query)
print(f"Запрос: {query}nКлассификация: {label} (уверенность: {score:.2f})n")Результат выполнения:
Запрос: Сколько стоит построить дом?
Классификация: фактический поиск (уверенность: 0.24)
Запрос: Как ты думаешь, погрузчик лучше, чем экскаватор?
Классификация: личный вопрос (уверенность: 0.28)
Запрос: Объясни принципы работы ДВС.
Классификация: рассуждение (уверенность: 0.34)
Запрос: Стоит ли мне переехать в другой город?
Классификация: мнение (уверенность: 0.30)
Запрос: Просто хочу поговорить.
Классификация: рассуждение (уверенность: 0.26)
На мой взгляд автоматизация этого процесса с помощью классификатора — это лучшее решение. Однако важно учитывать, что классификатор должен быть обучен на разнообразных данных, чтобы избежать ошибок в реальных сценариях.
Вот профессиональный рерайт с заголовками и улучшением структуры:
Разделение документов на фрагменты: ключ к эффективному поиску
Разделение документов на фрагменты является одним из самых важных этапов в обработке информации и поисковых системах. Этот процесс влияет на точность и эффективность поиска, особенно в рамках технологий поиска и генерации ответов на основе векторных представлений. Существует несколько подходов к фрагментации, и каждый из них имеет свои преимущества и недостатки в зависимости от задач.
Почему важно разделять документы на фрагменты?
Основная цель разделения текста на фрагменты заключается в оптимизации поиска. Векторные поисковые системы, такие как FAISS, Chroma и Weaviate, работают гораздо эффективнее с короткими фрагментами текста. Деление документов на меньшие части позволяет:
- Оптимизировать поиск: Короткие фрагменты проще индексируются и быстрее обрабатываются, что улучшает результаты поиска.
- Снизить поисковый шум: Большие фрагменты текста могут содержать нерелевантную информацию, что приводит к выдаче неактуальных результатов. Меньшие фрагменты помогают избегать этого.
- Обеспечить контекстную релевантность: Правильное разделение текста позволяет извлечь только необходимую информацию, что помогает избежать перегрузки LLM (Large Language Models) лишними данными.
Как делить документы на фрагменты?
Существует несколько подходов к разделению текста на фрагменты. Каждый из них имеет свои особенности и применяется в зависимости от сложности документа и требований к точности поиска.
Фиксированные фрагменты (Fixed-length chunking)
Этот метод подразумевает разбиение текста на фрагменты фиксированного размера, например, по 512 или 1024 токена.
- Преимущества:
- Простота реализации.
- Хорошо работает с длинными документами, где важен общий контекст.
- Недостатки:
- Может нарушить контекст, если текст приходится разрывать на границе фрагментов.
- Потеря смысла из-за искусственного разделения.
Семантические фрагменты (Semantic chunking)
Этот метод использует модели обработки естественного языка (NLP), такие как BERT, для разбиения текста по смысловым блокам — абзацам, заголовкам или смысловым единицам.
- Преимущества:
- Сохраняет логическую целостность текста.
- Повышает точность поиска и качество векторных представлений.
- Недостатки:
- Более сложная реализация.
- Размеры фрагментов могут быть неравномерными, что иногда затрудняет обработку.
Структурные фрагменты (Structural chunking)
Этот подход использует структуру документа для разбиения на логические единицы: заголовки, списки, таблицы и другие элементы.
- Преимущества:
- Идеален для технических документов, научных статей и справочников, где структура играет важную роль.
- Сохраняет контекст и логику, присущие структурированным данным.
- Недостатки:
- Требует предварительной обработки документов для выделения структурных элементов.
- Не всегда применимо к неструктурированным данным, где структура может быть неочевидной.
Выбор подхода к фрагментации
Каждый из методов разделения текста имеет свои преимущества в разных контекстах. Если вы работаете с длинными текстами, и важно сохранить общий контекст, может подойти метод фиксированных фрагментов. Однако для более точного поиска и сохранения смысла текста лучше использовать семантическое разделение, хотя оно и требует более сложной реализации. Если же документ обладает чёткой структурой (например, это техническая инструкция), подход с разделением по структурным элементам будет наиболее эффективен.
Правильное разделение документа на фрагменты помогает не только улучшить эффективность поиска, но и повысить точность ответов, получаемых из векторных баз данных и больших языковых моделей.
Пример фиксированного разделения по 512 токенов
from transformers import AutoTokenizer
# Загружаем токенизатор (используем BERT)
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
def chunk_text(text, max_tokens=512):
tokens = tokenizer.encode(text, add_special_tokens=False)
chunks = [tokens[i:i+max_tokens] for i in range(0, len(tokens), max_tokens)]
return [tokenizer.decode(chunk) for chunk in chunks]
# Тестовый текст
text = "Иску́сственный интелле́кт (англ. artificial intelligence; AI) в самом широком смысле — это интеллект, демонстрируемый машинами, в частности компьютерными системами. Это область исследований в области компьютерных наук, которая разрабатывает и изучает методы и программное обеспечение, позволяющие машинам воспринимать окружающую среду и использовать обучение и интеллект для выполнения действий, которые максимально увеличивают их шансы на достижение поставленных целей[1]. Такие машины можно назвать искусственным интеллектом. Некоторые из наиболее известных приложений искусственного интеллекта включают в себя передовые поисковые системы (например, Google Search, Bing, Яндекс); рекомендательные системы (используемые на YouTube, Amazon и Netflix); взаимодействие посредством человеческой речи (например, Google Assistant, Siri, Alexa, Алиса); автономные транспортные средства (например, Waymo); генеративные и творческие инструменты (например, ChatGPT, Apple Intelligence и искусство искусственного интеллекта); а также сверхчеловеческую игру и анализ в стратегических играх (например, шахматы и го). Однако многие приложения искусственного интеллекта не воспринимаются как искусственный интеллект: «Многие передовые разработки искусственного интеллекта проникли в общие приложения, часто не называясь искусственным интеллектом, потому что как только что-то становится достаточно полезным и достаточно распространённым, его больше не называют искусственным интеллектом»[2][3]. Алан Тьюринг был первым человеком, который провёл масштабные исследования в области, которую он назвал машинным интеллектом[4]. Искусственный интеллект был основан как академическая дисциплина в 1956 году[5] теми, кого сейчас считают отцами-основателями искусственного интеллекта: Джоном Маккарти, Марвином Мински, Натаниэлем Рочестером[англ.] и Клодом Шенноном[6][7]. Эта область пережила несколько циклов оптимизма[8], за которыми последовали периоды разочарования и потери финансирования, известные как зима искусственного интеллекта[9]. Финансирование и интерес значительно возросли после 2012 года, когда глубокое обучение превзошло все предыдущие методы искусственного интеллекта[10], а также после 2017 года с появлением архитектуры Transformer[11]. Это привело к буму искусственного интеллекта в начале 2020-х годов, когда компании, университеты и лаборатории, в подавляющем большинстве базирующиеся в Соединённых Штатах, стали пионерами значительных достижений в области искусственного интеллекта[12]. Растущее использование искусственного интеллекта в XXI веке влияет на общественный и экономический сдвиг в сторону большей автоматизации, принятия решений на основе данных и интеграции систем искусственного интеллекта в различные секторы экономики и сферы жизни, влияя на рынки труда, здравоохранение, государственное управление, промышленность, образование, пропаганду и дезинформацию. Это поднимает вопросы о долгосрочных эффектах, этических последствиях и рисках искусственного интеллекта, побуждая к обсуждениям о политике регулирования, направленной на обеспечение безопасности и преимуществ этой технологии. Различные направления исследований искусственного интеллекта сосредоточены вокруг определённых целей и использования определённых инструментов. Традиционные цели исследований искусственного интеллекта включают рассуждение, представление знаний, планирование, обучение, обработку естественного языка, восприятие и поддержку робототехники[13]. Общий интеллект, или же сильный, — способность выполнять любую задачу, которую может выполнить человек, по крайней мере на равном уровне — входит в число долгосрочных целей данной области[14]. Для достижения этих целей исследователи искусственного интеллекта адаптировали и интегрировали широкий спектр методов, включая поиск и математическую оптимизацию, формальную логику, искусственные нейронные сети, а также методы, основанные на статистике, исследовании операций и экономике[13]. Искусственный интеллект также опирается на психологию, лингвистику, философию, нейронауку и другие области[15]."
# Разбиваем на куски по 512 токенов
chunks = chunk_text(text)
for i, chunk in enumerate(chunks):
print(f"Фрагмент {i+1}:n{chunk}n")Результат выполнения:
Фрагмент 1: искусственный интеллект ( англ. artificial intelligence ; ai ) в самом широком смысле — это интеллект, демонстрируемыи машинами, в частности компьютерными системами. это область исследовании в области компьютерных наук, которая разрабатывает и изучает методы и программное обеспечение, позволяющие машинам воспринимать окружающую среду и использовать обучение и интеллект для выполнения деиствии, которые максимально увеличивают их шансы на достижение поставленных целеи [ 1 ]. такие машины можно назвать искусственным интеллектом. некоторые из наиболее известных приложении искусственного интеллекта включают в себя пере
Фрагмент 2: ##довые поисковые системы ( например, google search, bing, яндекс ) ; рекомендательные системы ( используемые на youtube, amazon и netflix ) ; взаимодействие посредством человеческой речи ( например, google assistant, siri, alexa, Алиса ) ; автономные транспортные средства ( например, waymo ) ; генеративные и творческие инструменты ( например, chatgpt, apple intelligence и искусство искусственного интеллекта ) ; а также сверхчеловеческую игру и анализ в стратегических играх ( например, шахматы и го ). однако многие приложения искусственного интеллекта не воспринимаются как искусственный интеллект: « многие передовые разработки искусственного интеллекта проникли в общие приложен
Фрагмент 3: ##ия, часто не называясь искусственным интеллектом, потому что как только что — то становится достаточно полезным и достаточно распространенным, его больше не называют искусственным интеллектом » [ 2 ] [ 3 ]. алан тьюринг был первым человеком, который провел масштабные исследования в области, которую он назвал машинным интеллектом [ 4 ]. искусственный интеллект был основан как академическая дисциплина в 1956 году [ 5 ] теми, кого сеичас считают отцами — основателями искусственного интеллекта : джоном маккарти, марвином мински, натаниэлем рочестером [ англ. ] и клодом шенноном [ 6 ] [ 7 ]. эта область пережила несколько цикл
Пример семантического разделения с использованием spaCy для разбиения текста на смысловые блоки:
import spacy
# Загружаем модель NLP
nlp = spacy.load("ru_core_news_sm")
def semantic_chunking(text, max_sentences=3):
doc = nlp(text)
sentences = [sent.text for sent in doc.sents]
# Группируем предложения по max_sentences
chunks = []
for i in range(0, len(sentences), max_sentences):
chunk = " ".join(sentences[i:i+max_sentences])
chunks.append(chunk)
return chunks
# Пример текста
text = "Иску́сственный интелле́кт (англ. artificial intelligence; AI) в самом широком смысле — это интеллект, демонстрируемый машинами, в частности компьютерными системами. Это область исследований в области компьютерных наук, которая разрабатывает и изучает методы и программное обеспечение, позволяющие машинам воспринимать окружающую среду и использовать обучение и интеллект для выполнения действий, которые максимально увеличивают их шансы на достижение поставленных целей[1]. Такие машины можно назвать искусственным интеллектом. Некоторые из наиболее известных приложений искусственного интеллекта включают в себя передовые поисковые системы (например, Google Search, Bing, Яндекс); рекомендательные системы (используемые на YouTube, Amazon и Netflix); взаимодействие посредством человеческой речи (например, Google Assistant, Siri, Alexa, Алиса); автономные транспортные средства (например, Waymo); генеративные и творческие инструменты (например, ChatGPT, Apple Intelligence и искусство искусственного интеллекта); а также сверхчеловеческую игру и анализ в стратегических играх (например, шахматы и го). Однако многие приложения искусственного интеллекта не воспринимаются как искусственный интеллект: «Многие передовые разработки искусственного интеллекта проникли в общие приложения, часто не называясь искусственным интеллектом, потому что как только что-то становится достаточно полезным и достаточно распространённым, его больше не называют искусственным интеллектом»[2][3]. Алан Тьюринг был первым человеком, который провёл масштабные исследования в области, которую он назвал машинным интеллектом[4]. Искусственный интеллект был основан как академическая дисциплина в 1956 году[5] теми, кого сейчас считают отцами-основателями искусственного интеллекта: Джоном Маккарти, Марвином Мински, Натаниэлем Рочестером[англ.] и Клодом Шенноном[6][7]. Эта область пережила несколько циклов оптимизма[8], за которыми последовали периоды разочарования и потери финансирования, известные как зима искусственного интеллекта[9]. Финансирование и интерес значительно возросли после 2012 года, когда глубокое обучение превзошло все предыдущие методы искусственного интеллекта[10], а также после 2017 года с появлением архитектуры Transformer[11]. Это привело к буму искусственного интеллекта в начале 2020-х годов, когда компании, университеты и лаборатории, в подавляющем большинстве базирующиеся в Соединённых Штатах, стали пионерами значительных достижений в области искусственного интеллекта[12]. Растущее использование искусственного интеллекта в XXI веке влияет на общественный и экономический сдвиг в сторону большей автоматизации, принятия решений на основе данных и интеграции систем искусственного интеллекта в различные секторы экономики и сферы жизни, влияя на рынки труда, здравоохранение, государственное управление, промышленность, образование, пропаганду и дезинформацию. Это поднимает вопросы о долгосрочных эффектах, этических последствиях и рисках искусственного интеллекта, побуждая к обсуждениям о политике регулирования, направленной на обеспечение безопасности и преимуществ этой технологии. Различные направления исследований искусственного интеллекта сосредоточены вокруг определённых целей и использования определённых инструментов. Традиционные цели исследований искусственного интеллекта включают рассуждение, представление знаний, планирование, обучение, обработку естественного языка, восприятие и поддержку робототехники[13]. Общий интеллект, или же сильный, — способность выполнять любую задачу, которую может выполнить человек, по крайней мере на равном уровне — входит в число долгосрочных целей данной области[14]. Для достижения этих целей исследователи искусственного интеллекта адаптировали и интегрировали широкий спектр методов, включая поиск и математическую оптимизацию, формальную логику, искусственные нейронные сети, а также методы, основанные на статистике, исследовании операций и экономике[13]. Искусственный интеллект также опирается на психологию, лингвистику, философию, нейронауку и другие области[15]."
# Разделяем на семантические фрагменты
chunks = semantic_chunking(text)
# Вывод результатов
for i, chunk in enumerate(chunks):
print(f"🔹 Фрагмент {i+1}:n{chunk}n")Результат выполнения:
Фрагмент 1:
Иску́сственный интелле́кт (англ. artificial intelligence; AI) в самом широком смысле — это интеллект, демонстрируемый машинами, в частности компьютерными системами. Это область исследований в области компьютерных наук, которая разрабатывает и изучает методы и программное обеспечение, позволяющие машинам воспринимать окружающую среду и использовать обучение и интеллект для выполнения действий, которые максимально увеличивают их шансы на достижение поставленных целей[1]. Такие машины можно назвать искусственным интеллектом.
Фрагмент 2:
Некоторые из наиболее известных приложений искусственного интеллекта включают в себя передовые поисковые системы (например, Google Search, Bing, Яндекс); рекомендательные системы (используемые на YouTube, Amazon и Netflix); взаимодействие посредством человеческой речи (например, Google Assistant, Siri, Alexa, Алиса); автономные транспортные средства (например, Waymo); генеративные и творческие инструменты (например, ChatGPT, Apple Intelligence и искусство искусственного интеллекта); а также сверхчеловеческую игру и анализ в стратегических играх (например, шахматы и го). Однако многие приложения искусственного интеллекта не воспринимаются как искусственный интеллект: «Многие передовые разработки искусственного интеллекта проникли в общие приложения, часто не называясь искусственным интеллектом, потому что как только что-то становится достаточно полезным и достаточно распространённым, его больше не называют искусственным интеллектом»[2][3]. Алан Тьюринг был первым человеком, который провёл масштабные исследования в области, которую он назвал машинным интеллектом[4].
Фрагмент 3:
Искусственный интеллект был основан как академическая дисциплина в 1956 году[5] теми, кого сейчас считают отцами-основателями искусственного интеллекта: Джоном Маккарти, Марвином Мински, Натаниэлем Рочестером[англ.] и Клодом Шенноном[6][7]. Эта область пережила несколько циклов оптимизма[8], за которыми последовали периоды разочарования и потери финансирования, известные как зима искусственного интеллекта[9]. Финансирование и интерес значительно возросли после 2012 года, когда глубокое обучение превзошло все предыдущие методы искусственного интеллекта[10], а также после 2017 года с появлением архитектуры Transformer[11].
Разделение на фрагменты, критически влияет на качество поиска и генерации. Выбор стратегии зависит от типа документов и задач системы.
- Фиксированные размеры — подходят для больших текстов.
- Семантическое разбиение — даёт более осмысленные куски.
- Структурное разбиение — полезно для технических данных. Лучший подход — комбинировать методы в зависимости от контекста!
Выбираем эмбеддинг модель
Embedding модель выполняет основную функцию в поиске релевантных документов. Опыт показывает, что важно сочетать высокую производительность с небольшим размером модели. Важно также отметить, что выбор модели может зависеть от конкретной задачи и доступных ресурсов.
Как это работает?
Модель преобразует текст в многомерное векторное представление. Эти векторы затем используются для поиска похожих фрагментов в базе данных.
При выборе модели важно определить:
Язык и специфику текстовых данных(домен)
- Если система работает на английском → OpenAI ada-002, BGE, SBERT
- Для русского → DeepPavlov/RuBERT, sbert_large_nlu_ru
- Для кодовых или медицинских данных → CodeBERT, BioBERT
Оптимальный размер векторов и скорость
- Короткие вектора (384–512) быстрее, но менее точны.
- Длинные вектора (1024+) дают точный поиск, но требуют больше памяти.
Способность к извлечению смысловых связей
- Косинусное сходство лучше работает с SBERT, BGE
- Для длинных текстов лучше подходят E5 или Cohere
Совместимость с базами данных
- Если используется FAISS/Chroma → SBERT, BGE, ada-002
- Если используется Milvus/Weaviate → OpenAI, Cohere

Пример векторизации данных
from sentence_transformers import SentenceTransformer
# Загружаем модель
model = SentenceTransformer("sentence-transformers/all-MiniLM-L6-v2")
# Примеры фрагментов текста
texts = [
"RAG использует внешнюю базу знаний для генерации ответов.",
"Модели встраивания помогают искать релевантную информацию.",
"Глубокие нейронные сети улучшают обработку естественного языка."
]
# Встраиваем текст в вектора
embeddings = model.encode(texts)
# Выводим размер вектора
print(f"Размер вектора: {len(embeddings[0])}")
print(f"Пример вектора: {embeddings[0][:5]}") # Выведем первые 5 значенийРезультат выполнения:
Размер вектора: 384
Пример вектора: [-0.00326376 0.07672146 0.01198601 -0.01142005 -0.04499646]
Выбираем векторную базу данных
Поскольку векторная база данных отвечает за хранение и быстрый поиск релевантных фрагментов информации. Выбор подходящей базы данных влияет на скорость работы, точность поиска и масштабируемость системы.
З что отвечает векторная база данных?
- Хранение текстовых фрагментов в виде многомерных векторов.
- Поиск наиболее похожих векторов по запросу.
- Использование индексов для быстрого поиска (ANN — Approximate Nearest Neighbors).
Я постарался выделить основные критерии при выборе
- Размер данных и масштабируемость Небольшой обьем данных → FAISS, Chroma Если нужен масштабируемый поиск → Weaviate, Milvus, Qdrant
- Скорость поиска Если важна быстрая обработка → FAISS, ScaNN (Google) Если важен онлайн-доступ и REST API → Weaviate, Pinecone
- Поддержка гибридного поиска (векторный + классический full-text) Weaviate, Qdrant, Vespa позволяют комбинировать векторный и текстовый поиск.
- Простота интеграции FAISS, Chroma — легко использовать в Python. Pinecone, Weaviate, Qdrant — удобны для облачных решений.

Пример поиска схожих векторов
import faiss
import numpy as np
from sentence_transformers import SentenceTransformer
# Загружаем модель встраивания
model = SentenceTransformer("all-MiniLM-L6-v2")
# Исходные текстовые фрагменты
texts = [
"Как работает RAG?",
"Векторные базы данных хранят embeddings.",
"Машинное обучение улучшает поиск информации.",
"Глубокие нейросети используются в NLP."
]
# Преобразуем текст в векторы
embeddings = model.encode(texts)
dimension = embeddings.shape[1] # Определяем размерность векторов
# Создаём индекс FAISS
index = faiss.IndexFlatL2(dimension)
index.add(np.array(embeddings)) # Добавляем векторы в базу
# Запрос (тоже преобразуем в вектор)
query = "Как работают векторные базы?"
query_embedding = model.encode([query])
# Ищем 2 ближайших вектора
D, I = index.search(np.array(query_embedding), k=2)
# Выводим результаты
print("Найденные фрагменты:")
for idx in I[0]:
print(f"- {texts[idx]}")
Результат выполнения:
Найденные фрагменты:
- Как работает RAG?
- Машинное обучение улучшает поиск информации.
Организуем Поиск и переранжирование
Методы поиска, такие как генерация запросов, значительно улучшают релевантность результатов. Однако хочу отметить, что эти методы могут быть ресурсоемкими, что важно учитывать в реальных приложениях.
- Поиск (Retrieval) На этом этапе система выполняет векторный поиск или гибридный поиск (комбинация векторного и классического текстового поиска).
Методы поиска:
- Векторный поиск (ANN – Approximate Nearest Neighbors): сравнение эмбеддингов запроса и базы (FAISS, Weaviate, Pinecone).
- Классический поиск (BM25): поиск по ключевым словам (Elasticsearch, Weaviate, Qdrant).
Гибридный поиск (BM25 + ANN): объединение двух методов для повышения точности.
- Переранжирование (Re-ranking) После поиска полученные документы ранжируются по релевантности. Простые методы (BM25) могут возвращать нерелевантные результаты, поэтому используется доранжировка (re-ranking) с помощью нейросетей.
Модели ранжирования:
- Cross-Encoder (SBERT) – дообученная модель для определения наиболее релевантных фрагментов.
- Cohere Rerank – облачная модель для улучшения поиска.
- OpenAI reranking (GPT) – доранжировка с помощью GPT.

Пример поиска и переранжирования
import faiss
import numpy as np
from sentence_transformers import SentenceTransformer, CrossEncoder
# Загружаем модели
retrieval_model = SentenceTransformer("all-MiniLM-L6-v2") # Для поиска
reranker = CrossEncoder("cross-encoder/ms-marco-MiniLM-L-6-v2") # Для переранжирования
# Исходные текстовые фрагменты
documents = [
"LLM могут генерировать ответы на основе найденных данных.",
"Поиск информации возможен через BM25 и векторный поиск.",
"Глубокие нейросети помогают анализировать текст.",
"RAG использует векторные базы данных для поиска."
]
# Преобразуем документы в эмбеддинги
doc_embeddings = retrieval_model.encode(documents)
dimension = doc_embeddings.shape[1]
# Создаём FAISS индекс
index = faiss.IndexFlatL2(dimension)
index.add(np.array(doc_embeddings))
# Запрос пользователя
query = "Как работает поиск в RAG?"
query_embedding = retrieval_model.encode([query])
# Поиск 3 ближайших фрагментов
D, I = index.search(np.array(query_embedding), k=3)
retrieved_docs = [documents[idx] for idx in I[0]]
# Переранжировка найденных документов
scores = reranker.predict([(query, doc) for doc in retrieved_docs])
ranked_docs = [doc for _, doc in sorted(zip(scores, retrieved_docs), reverse=True)]
# Вывод результатов
print("Найденные документы (после переранжировки):")
for doc in ranked_docs:
print(f"- {doc}")
Пример выполнения:
Найденные документы (после переранжировки):
RAG использует векторные базы данных для поиска.
Поиск информации возможен через BM25 и векторный поиск.
Глубокие нейросети помогают анализировать текст.
Реализуем резюмирование и генерацию ответа
Резюмирование извлеченных документов — это этап, который помогает устранить избыточность и улучшить качество ответов. Рекомендуется сочетать экстрактивные и генеративные подходы, такой подход обеспечивает высокую точность и эффективность.
После того, как система извлекла фрагменты из нашей базы знаний и провела их ранжирование, следует обработка текста для выделения ключевых идей:
В процессе обработки данных происходит удаление несущественных деталей: Например, могут быть убраны лишние слова или избыточная информация, не влияющая на ответ. Также может быть выполнено предобразование текста, что может включать переформулировку или упрощение фрагментов, чтобы сделать информацию более доступной для восприятия
Далее с помощью Подготовка контекста для генерации:
После извлечения релевантных документов и фрагментов, эти данные формируют контекст, который используется для генерации ответа.
Контекст включает как информацию из извлеченных документов, так и сам запрос пользователя. Важно, чтобы система правильно сопоставила запрос с нужными фрагментами из документов.
В некоторых случаях этот контекст дополнительно структурируется или очищается, чтобы исключить лишние или неподобающие данные, которые могут мешать генерации.генеративных моделей создается ответ на основе обработанных фрагментов.
Генеративная модель может взять информацию из множества фрагментов и «сжать» её в лаконичный и точный ответ. Лучше всего для таких задачподходят те модели , которые способны связно генерировать текст на основе предоставленного контекста. Также модели могут использовать механизмы внимания (attention) для «запоминания» ключевых частей контекста, необходимого для корректного ответа.
Последним частью обобщения является согласование. Важно, чтобы все данные в ответе были логично скомбинированы и не противоречили друг другу. Реализация должна отвечать принципам референтности, когда модели должны следить, чтобы ссылки на факты были точными, а также согласованности, когда ответ должен быть логично выстроен, чтобы не происходило резких скачков мыслей.
Модели для резюмирования в RAG-системах
T5 (Text-to-Text Transfer Transformer) — Модель, которая обучена на множестве текстовых задач и может выполнять задачи генерации текста, включая резюмирование.
Хорошо подходит для генерации резюме текста и формирования сжато сформулированного ответа.
BART (Bidirectional and Auto-Regressive Transformers) — Модель для сжимающего и абстрактного резюмирования. Работает как энкодер-декодер, извлекая информацию из текста и генерируя логичный, сжато изложенный ответ.
Преимущество следует отдавать моделям способным генерировать ответы с использованием предоставленного контекста. Например GPT Они могут не только осуществлять резюмирование, но и выполнять сложные генеративные задачи, включая диалоговые интерфейсы.
Пример простой суммаризации
from transformers import pipeline
# Загружаем модель для резюмирования (BART)
summarizer = pipeline("summarization", model="sberbank-ai/rugpt3small_sum")
# Пример текста
text = """
В Retrieval-Augmented Generation (RAG) используется две ключевые технологии: извлечение информации и генерация ответа.
Система сначала находит релевантные фрагменты из базы данных, а затем генерирует на основе этих фрагментов связанный ответ.
Процесс резюмирования помогает сделать ответы более лаконичными, снижая объем ненужной информации и представляя только основные факты.
"""
# Генерация резюме
summary = summarizer(text, max_length=50, min_length=25, do_sample=False)
# Вывод резюме
print("Обобщенный текст:", summary[0]['summary_text'])
Результат выполенния:
Обобщенный текст: В Retrieval-Augmented Generation (RAG) используется извлечение информации и генерация ответа. Резюмирование помогает снизить объем информации и представить только основные факты.
При выборе стратегий резюмирования в RAG-системах следует опираться на их особенности, при использовании сжимающего резюмирования (Extractive Summarization) система выбирает существенные фрагменты из исходного текста, не изменяя их, и объединяет их для формирования ответа. Такой подход проще, но ограничивает гибкость.
В случае применения абстрактного резюмирование (Abstractive Summarization) модель переформулирует исходные данные своими словами, что дает больше гибкости и возможность создавать более связные и логичные ответы. Это сложнее, но результат часто более точен и полезен.
Выбор стратегий построения RAG систем лежит между максиамльной производительностью включает все модули для достижения максимальной точности и сбалансировной эффективностью, данная стратегия оптимизирует производительность и эффективность, исключая некоторые ресурсоемкие методы.
На мой взгляд, выбор стратегии зависит от конкретных требований проекта. Например, если важна скорость обработки, можно пожертвовать некоторой точностью ради эффективности. Однако в задачах, где точность критически важна, лучше использовать все модули.
В этой статье я обратил внимание на несколько важных идей:
- Важность построения модульной конструкции: Оптимизация каждого компонента по отдельности позволяет создавать гибкие и легко настраиваемые системы. Это особенно важно в сложных проектах, где требования могут меняться со временем.
- Систематический подход к практической реализации: приведённый опыт демонстрирует, как тщательное тестирование на общепризнанных наборах данных может обеспечить надежность результатов. Данные примеры реализации могут пригодится, при выборе и анализе реализации этапов RAG .
- Существующие практические ограничения: Несмотря на все преимущества RAG, существуют проблемы, такие как обобщение на частные данные, производительность в реальном времени и интеграция многомодальных данных. Эти вопросы требуют дополнительного изучения при построении подобных систем .
На мой взгляд предложенные методы и стратегии могут значительно улучшить качество и эффективность систем RAG. Однако важно помнить, что каждая задача уникальна, и успешное внедрение RAG требует не только следования лучшим практикам, но и адаптации к конкретным условиям.





